
Introduction
Welcome. If you're managing physical assets—whether it's a fleet of vehicles, a power grid, or a manufacturing plant—you know that things break. The real question isn't if they will fail, but when, how, and what you're going to do about it. For decades, the prevailing wisdom was simple: wait for it to break, then fix it. This reactive approach is costly, disruptive, and in today's complex, interconnected world, simply not good enough.
We've moved into an era where maintenance is no longer a cost center hidden in the basement; it's a strategic driver of value, safety, and reliability. A well-oiled maintenance program doesn't just fix things—it anticipates failures, optimizes asset performance, and directly contributes to the organization's bottom line. This article will guide you through the foundational pillars of modern maintenance, moving from the simplest reactive methods to the sophisticated, data-driven strategies that define best-in-class asset management today.
The Starting Point: When Things Go Wrong
Every discussion about maintenance strategy has to start with the most basic form: fixing something after it has already failed. This is known as Corrective Maintenance (CM). Think of a lightbulb burning out. You don't perform maintenance on it beforehand; you simply wait for it to go dark and then replace it.
For non-critical, low-cost, and easily replaceable assets, this "run-to-failure" approach can be perfectly logical. Why spend time and money maintaining an asset when its failure has minimal impact and the fix is cheap and easy? The problem arises when this logic is misapplied to critical, complex, or expensive equipment. Imagine applying the lightbulb strategy to a primary water pump for a city or a critical server in a data center. The consequences of failure—service disruption, safety hazards, and massive secondary costs—are unacceptable. This is why we need more proactive approaches.
The First Step to Proactivity: A Schedule of Care
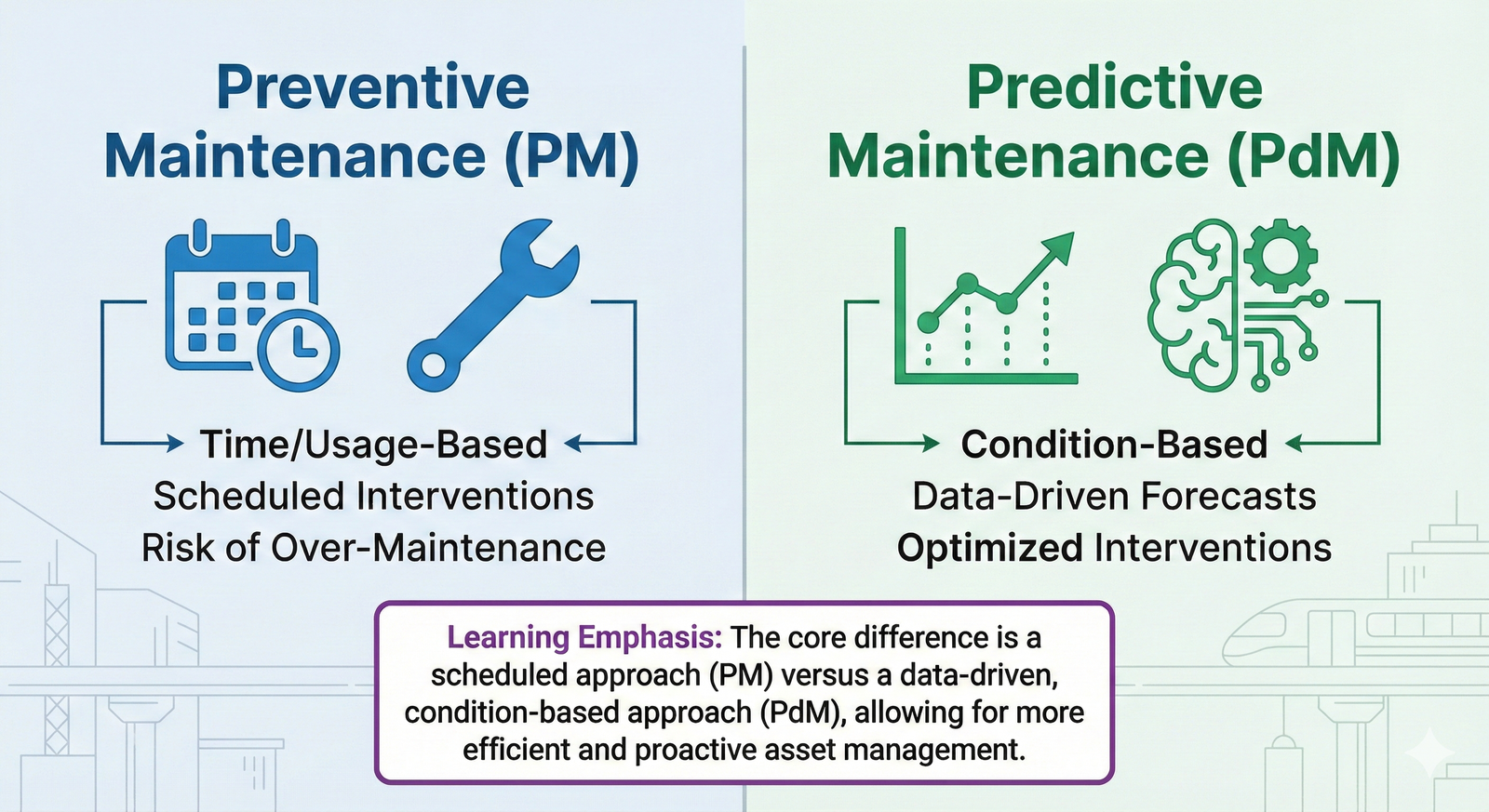
The most straightforward way to move from reactive to proactive is to service assets before they fail. This is the core idea behind Preventive Maintenance (PM). It operates on the assumption that assets degrade over a predictable lifecycle. By intervening at set points, you can reset the clock on that degradation and reduce the likelihood of an in-service failure.
The classic example is changing the oil in your car every 5,000 miles or every six months. You don't wait for the engine to seize. You perform the maintenance based on a schedule recommended by the manufacturer, who has determined the average lifespan of the oil under normal operating conditions.
In an industrial setting, a PM program is managed through a series of scheduled tasks. An asset manager or planner will issue a Work Order for a technician to inspect and lubricate a conveyor belt motor every 500 operating hours, or to replace the filters on an HVAC unit every quarter.
The Double-Edged Sword of Preventive Maintenance
PM is a massive leap forward from a purely reactive model. It brings predictability and reduces catastrophic failures. However, it has a significant drawback: it can lead to 'over-maintenance.' You might replace a component that still has 40% of its useful life remaining, simply because the schedule said so. This wastes resources, incurs unnecessary labor costs, and can even introduce new risks if the maintenance is performed incorrectly. The goal isn't just to prevent failure, but to do so efficiently.
Listening to Your Assets: The Rise of Condition-Based Thinking
What if, instead of relying on averages and schedules, you could ask your assets how they're doing? That's the fundamental shift introduced by Condition-Based Maintenance (CBM). CBM moves away from the "when" (time/usage) of PM and focuses on the "what" (the asset's actual health).
This is where technology begins to play a much larger role. Instead of just looking at a calendar, maintenance teams use various tools to gather data about an asset's condition. This could be as simple as a technician performing a visual inspection or as advanced as using sophisticated sensors.
A more advanced evolution of CBM is Predictive Maintenance (PdM). While CBM triggers maintenance when a threshold is crossed (e.g., "the vibration has exceeded 5mm/s"), PdM uses data trends to forecast when that threshold will be crossed. It answers the question: "Given the current rate of degradation, when is this component likely to fail?"
Common PdM technologies include: * Vibration Analysis: Used on rotating equipment like motors, pumps, and turbines. Changes in vibration patterns can indicate bearing wear, misalignment, or imbalance. * Thermal Imaging: Infrared cameras can detect abnormal heat signatures, which can point to issues like loose electrical connections, friction from worn parts, or blockages in cooling systems. * Oil Analysis: Analyzing lubricant samples can reveal the presence of microscopic metal particles, indicating internal wear on gears or bearings long before it becomes catastrophic. * Acoustic Analysis: Listening for changes in the sound an asset makes can identify issues like gas leaks or failing components.

This data-driven approach allows for "just-in-time" maintenance, maximizing the useful life of components while still avoiding unplanned downtime.
The Overarching Philosophy: Doing the Right Maintenance at the Right Time
So, which strategy is best? Corrective? Preventive? Predictive? This is a trick question. The answer is "all of them." A world-class maintenance program doesn't choose one strategy; it develops a blended Maintenance Strategy that applies the most appropriate and cost-effective technique to each asset. The framework for making these decisions is Reliability-Centered Maintenance (RCM).
RCM isn't a maintenance type like PM or PdM; it's a decision-making process. It forces you to ask a series of structured questions for each critical asset: 1. What are the asset's functions? 2. In what ways can it fail to fulfill its functions (functional failures)? 3. What causes each functional failure (failure modes)? 4. What happens when each failure occurs (failure effects)? 5. In what way does each failure matter (failure consequences)? 6. What can be done to predict or prevent each failure (proactive tasks)? 7. What should be done if a suitable proactive task cannot be found (default actions)?
📊 View Diagram: Simplified RCM Decision Logic
By going through this rigorous process, you might decide that for a critical, high-wear pump, a PdM strategy using vibration analysis is justified. For a less critical but still important HVAC unit, a time-based PM strategy of replacing filters and belts is sufficient. And for the office lightbulbs, a run-to-failure CM strategy is the most economical choice. RCM provides the logic to build this optimized, blended strategy.
Measuring Success: How Do You Know If It's Working?
Developing a strategy is one thing; knowing if it's effective is another. Two of the most fundamental metrics in the world of maintenance and reliability are Mean Time Between Failures (MTBF) and Mean Time To Repair (MTTR).
Think of it this way: * MTBF tells you how good you are at preventing failures. A high MTBF means your assets are reliable and your proactive maintenance strategies are working. * MTTR tells you how good you are at responding to failures. A low MTTR means your technicians are well-trained, have the right parts and tools, and can get assets back online quickly.
An effective maintenance strategy aims to increase MTBF and decrease MTTR. By tracking these metrics over time for your critical assets, you can quantify the impact of your program and identify areas for improvement. If you implement a new PdM program on your primary compressors and their MTBF doubles over the next year, you have a clear, data-backed justification for the investment.
Closing
We've journeyed from the simple act of fixing a broken part to the strategic implementation of a comprehensive maintenance philosophy. The pillars of modern maintenance—Corrective, Preventive, Predictive, and the overarching framework of Reliability-Centered Maintenance—are not competing options. They are a suite of tools in the modern asset manager's toolkit.
The goal is not to eliminate all failures but to eliminate all unplanned and consequential failures in the most economically efficient way possible. This requires a shift in mindset: from seeing maintenance as a necessary evil to embracing it as a data-informed, strategic function that underpins the safety, reliability, and profitability of your entire operation. By understanding these core strategies, you are equipped to start building a program that doesn't just react to the present but actively shapes a more reliable future.
Learning Outcomes
In this reading, you have built a foundational understanding of modern maintenance strategies. You can now effectively differentiate between the core approaches used in professional asset management.
You are now able to: - Distinguish between reactive (Corrective) and proactive (Preventive, Predictive) maintenance. - Explain the logic, benefits, and drawbacks of Preventive Maintenance (PM) versus Predictive Maintenance (PdM). - Define the role of Reliability-Centered Maintenance (RCM) as a strategic framework for selecting the appropriate maintenance tasks. - Recognize key terms such as Condition-Based Maintenance (CBM), Work Order, Mean Time Between Failures (MTBF), and Mean Time To Repair (MTTR) and understand their role in a maintenance program.
Assess Yourself
❓ Knowledge Check
Test your understanding of the key concepts from this section.
Next Steps
You have successfully reviewed the foundational strategies that govern modern asset management. This is a critical step in learning how to manage infrastructure and physical assets effectively. Please navigate back to the course to continue your learning journey.
